K-nearest neighbour
Inleiding
Het K-Nearest Neighbours (KNN) algoritme is een eenvoudig en veelgebruikt classificatie- en regressiealgoritme in machine learning. Het valt onder de categorie van toezichtsleeralgoritmen, en het wordt ingezet voor classificatie, waarbij het doel is om een klasselabel toe te wijzen aan een invoerpunt, en regressie, waar het doel is om een continu numerieke waarde te voorspellen op basis van invoergegevens.Wat is K-Nearest Neighbours?
K-Nearest Neighbours (KNN) is een algoritme dat wordt gebruikt voor classificatie en regressie. Bij classificatie wijst het een klasselabel toe aan een datapunt, terwijl het bij regressie een continue numerieke waarde voorspelt. KNN is eenvoudig te begrijpen en te implementeren, waardoor het een populair keuze is, vooral voor beginners in machine learning.Hoe werkt het?
Het KNN-algoritme werkt eigenlijk heel simpel. Stel je hebt een nieuw datapunt, en je wilt weten tot welke groep het behoort of welke waarde het heeft. Het algoritme kijkt naar de "k" dichtstbijzijnde bekende datapunten en kiest op basis daarvan wat het nieuwe punt zou moeten zijn. Een paar voorbeelden van afstandsmetingen van KNN zijn:Euclidische Afstand:
• De meest gebruikte afstandsmeting in KNN.
• Berekent de rechte lijn afstand tussen twee punten in de kenmerkruimte.
• Geschikt voor continue numerieke kenmerken.
Manhattan Afstand (City Block Afstand):
• Berekent de afstand tussen twee punten door de absolute verschillen tussen hun coördinaten langs elke dimensie op te sommeren.
• Praktisch bij het omgaan met kenmerken gemeten in verschillende eenheden.
Hamming Afstand:
• Gebruikt voor het vergelijken van binaire of categorische gegevens.
• Meet het aantal posities waarop twee strings van gelijke lengte verschillen.
Trainingsfase:
Tijdens de training onthoudt het algoritme gewoon de kenmerken en bijbehorende labels of waarden van de bekende voorbeelden.
Voorspellingsfase:
• Als we een nieuw datapunt hebben, meet het algoritme hoe ver het is van alle bekende datapunten.
• Daarna kiest het de "k" dichtstbijzijnde datapunten gebaseerd op die afstanden.
• Voor classificatie geeft het algoritme het meest voorkomende klasselabel van die dichtstbijzijnde buren aan het nieuwe datapunt.
• Voor regressie berekent het algoritme het gemiddelde van de doelwaarden van die dichtstbijzijnde buren en dat wordt de voorspelde waarde voor het nieuwe datapunt.
Keuze van "k"
De keuze van de parameter "k" is essentieel in het KNN-algoritme. Er is geen optimale "k"-waarde die werkt voor alle datasets en problemen. De keuze van "k" moet gebaseerd zijn op een combinatie van experimenten en op basis van de gegevens. Onthoud dat een kleine "k"-waarde kan leiden tot gevoeligheid voor ruis, terwijl een grote "k"-waarde kan resulteren in het verlies van patronen. Een paar methoden om een goede keuze van een "k"-waarde te krijgen zijn:Kruisvalidatie:
• Split uw dataset in meerdere vouwen
• Train voor elke vouw het KNN-model met verschillende "k"-waarden en evalueer de prestaties op de validatieset.
• Bereken het gemiddelde prestatiecijfer (bijvoorbeeld nauwkeurigheid) voor elke "k"-waarde over alle vouwen.
• Kies de "k"-waarde die resulteert in de beste gemiddelde prestaties.
Oneven versus Even "k"-waarden:
• Kies oneven "k"-waarden om onbeslistheid bij het classificeren van datapunten met een gelijk aantal dichtstbijzijnde buren van verschillende klassen te voorkomen.
• Het gebruik van een oneven "k"-waarde voorkomt twijfelachtigheid bij classificatie.
Elleboogmethode:
• Teken het prestatiecijfer (bijvoorbeeld nauwkeurigheid) uit als een functie van verschillende "k"-waarden.
• Zoek naar het punt op de plot waar de prestaties stabiliseren of beginnen af te nemen. Dit punt lijkt op een "elleboog."
• Deze methode helpt u bij het identificeren van een "k"-waarde die een goede balans biedt tussen bias en variantie.
Voor en nadelen
Voordelen:
KNN is niet moeilijk om te leren en te gebruiken, dus het is perfect voor mensen die nieuw zijn in machine learning. KNN kan werken met verschillende soorten informatie, zoals getallen en categorieën. Een ander cool ding is dat KNN geen speciale training nodig heeft. Het onthoudt gewoon wat het heeft gezien en kan dus ook zo nieuwe dingen leren. Het kan slimme keuzes maken, zelfs als de grenzen tussen verschillende groepen niet zo duidelijk zijn. En het beste van alles is dat KNN geen rare aannames doet ook kan het werken als er een ingewikkelde relatie is tussen dingen.Nadelen:
Als we denken aan snelheid, nou, KNN kan een beetje langzaam zijn als het veel informatie moet verwerken. Voor grote groepen gegevens kan het even duren. KNN is ook gevoelig voor rare dingen. Als er rare gegevens zijn kan het een beetje in de war raken, vooral als "k" te klein is. Het kiezen van de juiste "k" is ook belangrijk. Als we te weinig buren vragen, kunnen we wat informatie missen. Als we te veel buren vragen, krijgen we misschien te algemene antwoorden. KNN meet de afstanden. Als we een rare manier kiezen om te meten hoe ver dingen uit elkaar liggen, kan het een aparte antwoorden geven. En KNN let niet echt op hoe belangrijk iets is. Het behandelt alle data gelijk, dus als sommige data niet echt belangrijk is, kan dat leiden tot resultaten die niet kloppenVoorbeeld van DivTag
Je hebt de volgende data: Lengte en gewicht van honden en katten. Je gebruikt de data en classificeert dat een bepaalt gewicht katten zijn- en boven dat gewicht, honden. Zoals je je kunt zien in de onderstaande afbeelding:
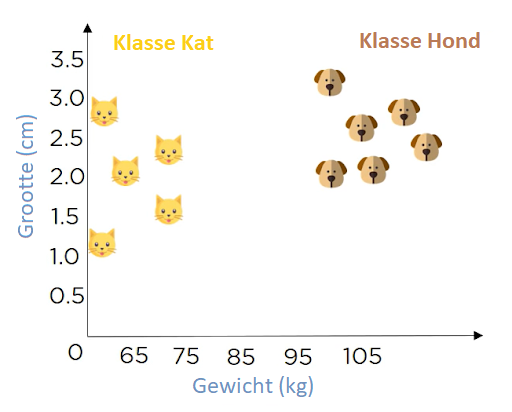
Nu heb je een nieuw datapunt en wil je bepalen of het een kat of een hond is
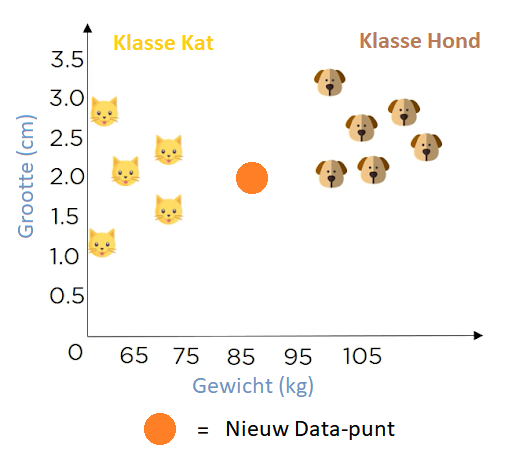
Dat is waar de waarde K een rol speelt dus moeten we de waarde van K specificeren. Dus laten we zeggen dat de waarde K = 3. Nu moeten we de 3 gegevenspunten vinden die we al hebben, die het dichtst bij het nieuwe datapunt liggen.
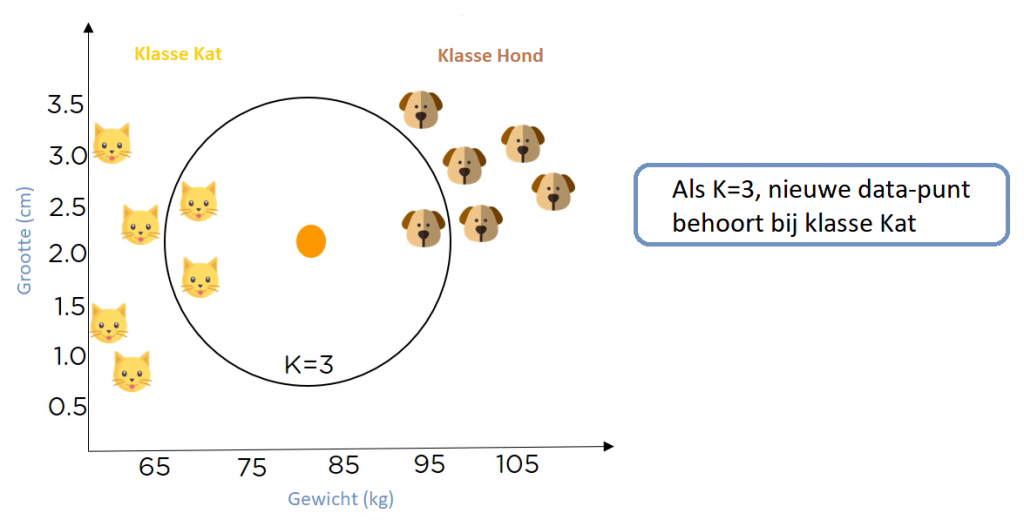
Nu zie je dat er in dit bereik meer katten dan honden zijn. Dus als K = 3, dan behoort de nieuwe data punt tot klasse "Kat". Wat gebeurt er als we vaststellen dat K in wachtrij staat bij 7. Daarom is K = 7, het nieuwe gegevenspunt behoort tot klasse Hond.
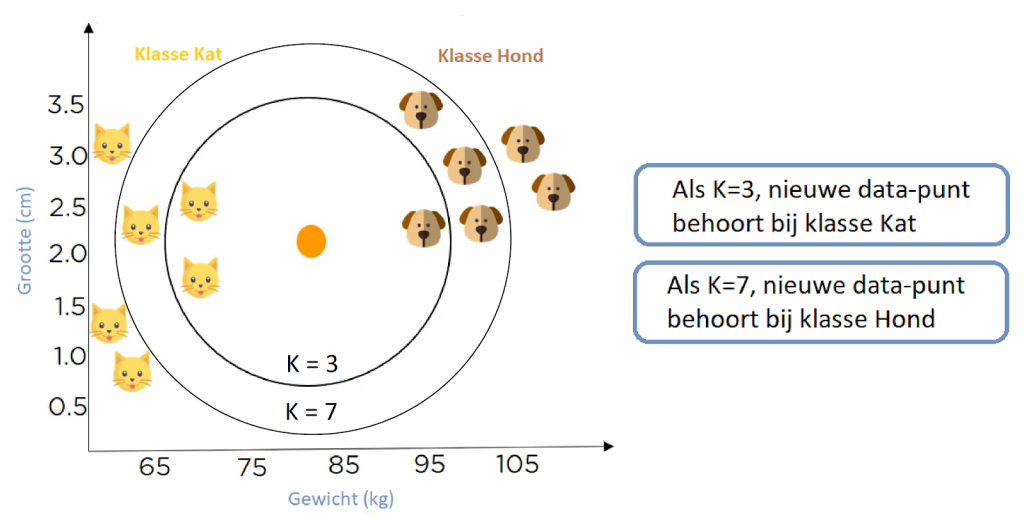
Met vallen en opstaan moeten we de juiste waarde van K kunnen vinden en dat gebruiken we. Dat is hoe we het model trainen.
toepassingen in de samenleving
Data Voorbereiden:
Soms ontbreken er gegevens in datasets. Het KNN-algoritme kan helpen door te raden wat die ontbrekende waarden zouden kunnen zijn. Dit is handig bij het voorbereiden van gegevens.Aanbevelingen op Websites:
Stel je voor dat je op een website bent en het KNN-algoritme wordt gebruikt om te begrijpen wat je leuk vindt op basis van wat andere mensen leuk vinden. Hierdoor kunnen ze je automatisch suggesties doen voor andere dingen die je interessant zou kunnen vindenIn de Financiële Wereld:
Banken gebruiken het KNN-algoritme om risico's van leningen te beoordelen. Het helpt bij het beslissen of een persoon of bedrijf betrouwbaar genoeg is om een lening te krijgen.In de Gezondheidszorg:
Voor de gezondheidszorg voorspelt het KNN-algoritme risico's op dingen zoals hartaanvallen en prostaatkanker. Het doet dit door naar genexpressies te kijken, wat iets zegt over waarschijnlijkheid waarmee bepaalde genen actief zijn.Patroonherkenning:
KNN helpt ook bij het herkennen van patronen, zoals bij het lezen van handschriften of het identificeren van cijfers. Stel je voor dat je met de hand geschreven cijfers op formulieren of enveloppen hebt, het KNN-algoritme kan helpen bij het begrijpen en herkennen van die cijfers. Dus, in eenvoudige bewoordingen, het k-NN algoritme wordt gebruikt om dingen te sorteren, aanbevelingen te doen op websites, risico's te beoordelen in de financiële wereld, gezondheidsrisico's te voorspellen, en zelfs om patronen te herkennen zoals bij het lezen van handschriften.